안녕하세요. 이번 시간엔 해당 논문을 직접 구현해보겠습니다. 블로그에 나온 설명은 요약해서 올린 설명입니다.
전체 코드는 아래 홈페이지에서 자세히 보실 수 있습니다. (함수 부분은 너무 길어서 여기에 올리지 않았습니다)
Hwan-I/Study
Contribute to Hwan-I/Study development by creating an account on GitHub.
github.com
코드 구현할 때 참고한 곳은 다음과 같습니다.
https://github.com/jsongcat/movie_recommendation_system
jsongcat/movie_recommendation_system
A movie recommendation system. Contribute to jsongcat/movie_recommendation_system development by creating an account on GitHub.
github.com
1. 첫 번째로 데이터를 불러옵니다.

데이터의 경우 MovieLens의 100k 데이터를 사용했으며 아래 사이트에서 다운 받으실 수 있습니다.
grouplens.org/datasets/movielens/100k/
MovieLens 100K Dataset
MovieLens 100K movie ratings. Stable benchmark dataset. 100,000 ratings from 1000 users on 1700 movies. Released 4/1998. README.txt ml-100k.zip (size: 5 MB, checksum) Index of unzipped files Permal…
grouplens.org
2. 데이터를 train과 test로 나누고 데이터를 dict, list 형태로 변환합니다.
○ test로 나누는 것은 test 데이터는 유사도 측정에 활용하면 안되기 때문입니다. 저는 논문에서 나온 80%를 train 데이터로 하겠습니다.

3. cross validation을 위해 train을 train과 valid로 나누고 모델링합니다. 논문에서 10개로 나눴기 때문에 저도 똑같이 10개로 나누도록 하겠습니다.
○ 각 유사도에 대해 평균값을 user, item를 더한 사례와 안 더한 사례로 나누어 분석합니다 : 총 90개의 결과가 나옵니다.
● 유사도 3개 * 평균값 관련 사례 3개 = 9개의 결과
● 9개 결과 * 10(cross-validation) = 90개
- 원래는 이 중 제일 잘 나온 결과를 test data에 적용하는 것이 맞으나 논문구현을 위해 이 부분은 생략하고 전체 결과를 test data에 적용합니다.
○ 아래는 변수에 대한 간단한 설명입니다.
● data_list : list에 데이터를 [user, item, rating] 구조로 넣음
ex) [[100, 1000, 3], [101, 1001, 4], ...]
● tra_user_dict : user, item, rating을 dict 형태로 넣음. 여기선 user가 key값이 되며 tra는 train을 의미함
ex) tra_user_dict[100][1000] = 3 : user 100의 item 1000에 대한 점수는 3점
● tra_item_dict : item을 key값으로 user, rating을 dict 형태로 넣음
● tra_user_mean_dict : 각 user를 key값, 각 user의 평균 점수 값을 value로 넣음


4. weighted sum : 위에서 만든 cross-validation으로 유사도를 구했으니 각 유사도 값으로 test 데이터의 예측 점수를 구합니다. 총 9개의 결과값이 나옵니다.(유사도 3개 * 평균값 관련 사례 3개)
○ cross validation은 각각 예측값을 구하고 이들을 평균값으로 해서 최종 예측값을 구합니다.


5. 예측값을 비교합니다. Adjusted_Cosine의 user를 평균값 기준으로 했을 때 제일 좋은 결과가 나옵니다.
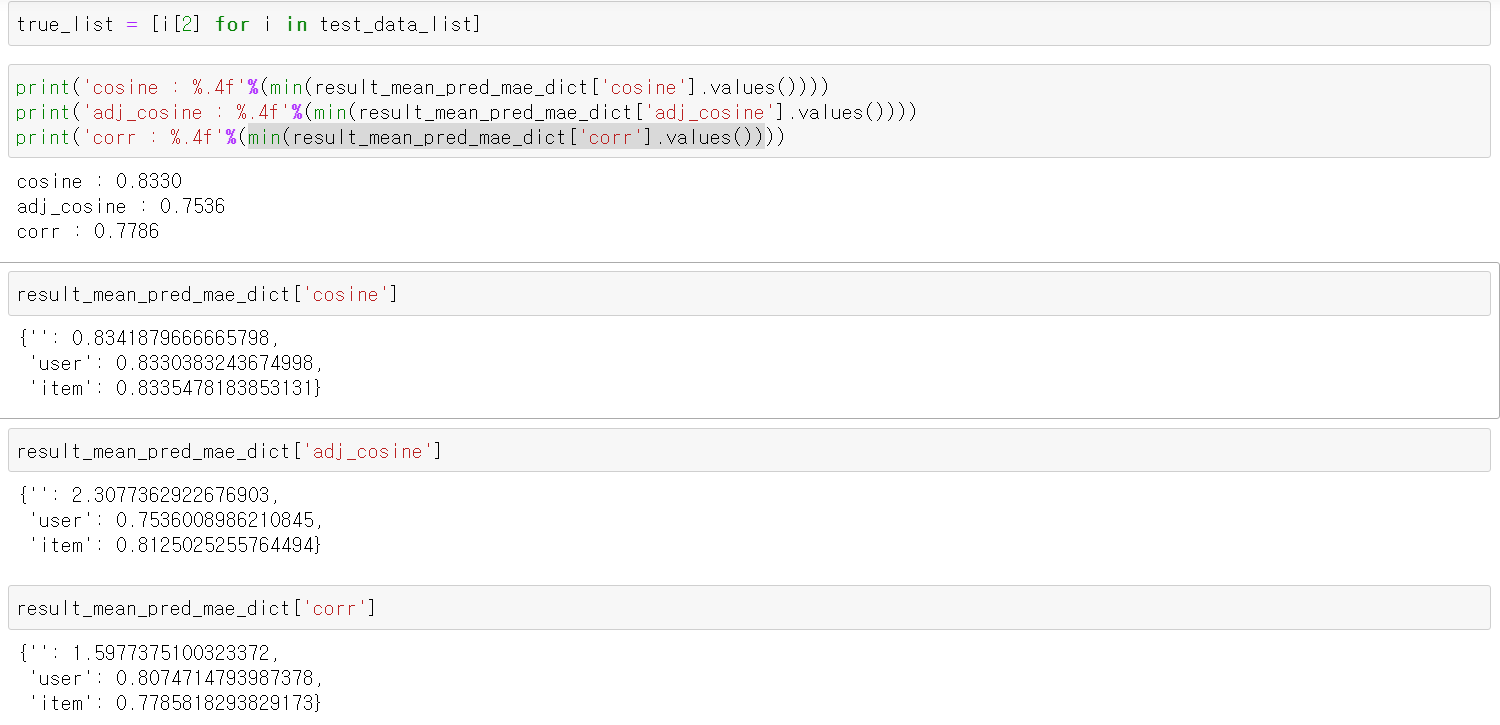
논문에서는 아래와 같은 결과가 나옵니다.

논문에서는 Correlation을 사용했을 때 MAE 값이 꽤 높게 나오는데 regression을 사용한 결과인지, 평균값을 어떤 것을 적용한 결과인지 알 수 없어 제 결과가 비교하기는 좀 애매한 것 같습니다. 어쨌든 Adjusted Cosine이 제일 성능이 좋은 것은 사실로 나와서 해당 방법에 대한 실험은 여기서 마무리 하려 합니다.
긴 글 읽어주셔서 감사합니다. 궁금하신 부분이나 수정할 부분 있으면 말씀해주세요!
'모델 > 추천시스템' 카테고리의 다른 글
| Collaborative Metric Learning (0) | 2021.04.15 |
|---|---|
| Probabilistic Matrix Factorization (알고리즘) (1) | 2020.12.08 |
| Item-Based Collaborative Filtering Recommendation Algorithms (1) (0) | 2020.12.01 |
| Neural Collaborative Filtering(2) - 알고리즘 및 결과 (0) | 2020.11.15 |
| Neural Collaborative Filtering(1) - 도입부 (0) | 2020.11.10 |


