안녕하세요!
이번 시간엔 추천시스템에서 model-based의 matrix factorization 방법인 SVD 관련 알고리즘을 보도록 하겠습니다.
참고한 자료는 다음과 같습니다.
Incremental Singular Value Decomposition Algorithms for Highly Scalable Recommender Systems (B Sarwar외, 2002)
: 오늘 설명할 알고리즘의 논문
Application of Dimensionality Reduction in Recommender System (B Sarwar외, 2000)
: folding-in 방법에 대한 논문
Evaluation of standard SVD-based techniques for Collaborative Filtering (M Vozalis외, 2009)
: matrix factorization을 할 때 평가하는 방법에 대한 논문
https://drive.google.com/file/d/0BylQe2cRVWE_RmZoUTJYSGZNaXM/viewdrive.google.com/file/d/0BylQe2cRVWE_RmZoUTJYSGZNaXM/view
: matrix factorization을 할 때 평가하는 방법에 대한 논문
Bachelor_thesis_ibrahim_incremental_svd.pdf
drive.google.com
www.ismll.uni-hildesheim.de/lehre/semML-16w/script/Group3_slides.pdf
: 오늘 설명할 알고리즘의 논문에 대한 수식 관련 글
오늘 소개드릴 방법은 2002년에 나온 오래된 방법입니다(실험용 컴퓨터가 팬티엄 3라고 했으니 말 다했다고 보셔도 될 것 같습니다...;)
(급하신 분들은 이 단락은 통과하셔도 됩니다)
저자는 추천시스템에서 rating을 가지고 추천할 때 발생하는 Sparse 문제를 해결하기 위해 Latent Semantic Indexing(LSI) 방법을 얘기합니다. LSI란 차원축소기술로 Information Retrieval(IR, 정보검색)에서 동의어, 다의어 등의 문제를 해결하기 위해 고안한 방법이라고 합니다. 여기서 IR이란 '집합적인 정보로부터 원하는 내용과 관련된 정보를 얻어내는 행위'를 말합니다(출처 : 위키백과). 쉽게 얘기하면 우리가 도서관에서 책을 찾을 때 검색하는 행위 등을 말합니다. 여기서 동의어, 다의어 때문에 정확한 정보 검색에 어려움이 있는데 이 때 차원축소를 활용하여 이를 해결한다고 합니다(이 부분은 위키백과의 내용을 그대로 해석한 것이라 정확하지 않을 수도 있습니다) 이러한 차원축소는 우리가 추천시스템에서 아는 Matrix Factorization이 해당됩니다. 즉, rating 정보르 추천할 때 발생하는 Sparse 문제를 LSI의 아이디어를 빌려와 Matrix Factorization을 적용하여 해결한다고 보시면 되겠습니다.
여기서 저자는 Matrix Factorization으로 SVD를 활용하나, SVD의 decomposition 비용이 커서 이를 낮추기 위해 Folding-in을 적용한 SVD를 씁니다(SVD를 잘 모르시면 여기 사이트나 다른 사이트에서 미리 공부해 오셔도 좋을 것 같습니다).
[선형대수학 #4] 특이값 분해(Singular Value Decomposition, SVD)의 활용
활용도 측면에서 선형대수학의 꽃이라 할 수 있는 특이값 분해(Singular Value Decomposition, SVD)에 대한 내용입니다. 보통은 복소수 공간을 포함하여 정의하는 것이 일반적이지만 이 글에서는 실수(real
darkpgmr.tistory.com
Folding-in을 적용한 방법은 다음과 같습니다.
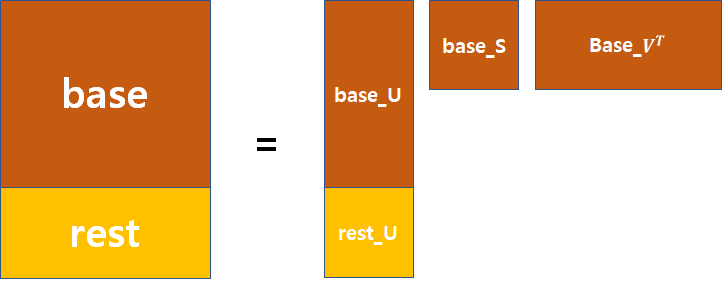
1. rating 정보를 가진 user-item matrix에서 x명의 user는 base로, 나머지는 rest로 놓습니다.
○ 예를 들어 943 x 1682의 matrix고 x가 600이면 600 x 1682는 base matrix, 343 x 1682는 rest matrix로 됩니다.

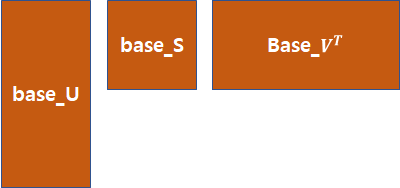
2. base matrix에 대해 SVD를 적용하여 U, S, $V^{T}$로 만듭니다.(앞에 base가 붙음)
3. rest matrix에 대해서는 SVD의 U로만 만들 것입니다. base_U에 rest matrix의 user만 반영한다면 다음과 같은 그림이 만들어 질 것입니다. 여기서 우리는 rest_U를 구해서 base와 rest를 나누기전의 matrix로 복구시킬 것입니다.
3-1. SVD 수식을 보면 다음과 같습니다.
$R = U S V^{T}$
여기서 R은 m x n matrix이며 U, S, $V^{T}$는 각각 SVD의 decomposition 값입니다. 만약 여기서 R의 1개 row 값인 i번째 row의 decomposition 결과는 다음과 같습니다.
$ d_{i} = U_{i} S V^{T}$
여기서 사이즈는 (1 x n) = (1 x k) (k x k) (k x n)이 됩니다.
이를 활용하여 rest_U는 다음과 같이 구할 수 있습니다.
$rest = restU S V^{T}$
$restU = rest V S^{-1}$
이 식을 적용하면 base와 rest가 반영된 incremental SVD 결과를 얻을 수 있습니다.
여기까지가 알고리즘에 대한 설명이었습니다. 다음 시간에는 코드로 결과까지 설명드리겠습니다.
읽어주셔서 감사합니다. 혹시 잘못된 부분이나 궁금하신 부분 있으시면 말씀해주세요!
'모델 > 추천시스템' 카테고리의 다른 글
| Neural Collaborative Filtering(2) - 알고리즘 및 결과 (0) | 2020.11.15 |
|---|---|
| Neural Collaborative Filtering(1) - 도입부 (0) | 2020.11.10 |
| 추천시스템 - Incremental Singular Value Decomposition Algorithms(2) (0) | 2020.10.14 |
| 추천시스템 - 기초2 (0) | 2020.10.08 |
| 추천시스템 - 기초 (0) | 2020.10.08 |


