안녕하세요! 이번 시간에는 자연어 처리의 기본적인 word2vec에 대해 글을 쓰겠습니다! 아마 한동안은 제가 자연어 모델들을 공부할 목적을 가져서 자연어 위주로 글이 올라올 것 같아요!(물론 다른 작업도 하다보니 그쪽 관련 글도 올라올 수 있습니다!)
이번 시간에 참고한 글은 다음과 같습니다.
○ word2vec 관련 논문 : 저자가 원래 쓴 설명 형식으로 쓴 글인데 저는 여기 설명이 더 와닿아서 이 글을 참조했습니다.
word2vec의 경우 글을 나누고자 합니다. 이는 (1)의 경우 word2vec을 이해하기 위한 기초 모델이기 때문입니다. 혹시 행렬곱 구조, one word context 구조를 아시는 분은 그냥 통과하셔도 됩니다.
우선 자연어 처리란 무엇일까요? 한국어 위키를 보면 '인간의 언어 현상을 컴퓨터와 같은 기계를 이용해서 모사 할 수 있도록 연구하고 이를 구현하는 인공지능의 주요 분야 중 하나'라고 정의하고 있습니다. 이는 우리가 흔히 접하는 번역기, 태그 분석, 영화 리뷰 분석 등 다양한 분야에서 쓰일 수 있는 기술입니다. 크게 통계적인 모델과 머신러닝 등의 모델을 활용한 모델로 나뉘는데 이번 모델은 후자에 해당하는 모델입니다.
word2vec 모델은 간단하게 input 단어를 주었을 때 어떤 output 단어가 나오도록 만드는 것인데 embedding 방식과 neural network(hidden layer가 1개이므로 deep learning이라 하기엔 애매합니다)를 을 활용한다는 점이 타 모델과의 차이라고 할 수 있습니다. continuous bag-of-word (CBOW), skip-gram 모델이 있는데 우선은 이 모델들의 기초가 되는 모델부터 보도록 하겠습니다.
※ 혹시 딥러닝 쪽 공부를 안하신 분이라면 미리 하고 오시는 것을 추천드립니다. 이 글에서 딥러닝 관련 용어에 대한 설명은 거의 없습니다.
One word context
1. 구조

그림 1은 neural network 구조로 된 one word context입니다. 여기서 context란 input 단어에 의해 나온 단어 결과인데 skip-gram은 3개의 단어를 context라고 표현합니다. 여기 예제에서는 단어 1개를 넣으면 어떤 단어가 그 다음 나와야 하는지 예측하는 것이죠. 예를 들면 'your'라는 단어를 input하면 다음에 'name'이라는 단어가 나오는 형태입니다.
각각을 소개하면
x : input vector입니다. 여기서는 one-hot-encoding을 한 것으로 'your'라는 단어는 여기서 [0, 0, 1, 0]과 같이 1개 값만 1이고 나머지는 0값으로 encoding 한 것입니다.
h : hidden vector입니다.
u : output vector입니다. 결과 역시 one-hot-encoding으로 나오는데 예를들어 'name'이라는 단어는 [0, 0, 0, 1]으로 되어있다면 이 값을 output으로 만들어 내는게 목표가 됩니다.
* 진하게 쓴 글씨(bold체)는 보통 vector 또는 matrix를 의미합니다(논문의 경우 문자 위에 밑줄을 넣는 경우도 있습니다)
여기서 중요한 것은 저기 위의 w, w*입니다. (논문에서 w*는 $w\prime$인데 키보드에 적절한 단어가 없어서 프라임을 *로 대체했으며 이는 혼용되어 쓰일 것입니다)
w, w*는 각각 input vector를 hidden vector로, hidden vector를 output vector로 만들 때 사용되는 가중치로 각각 W, W*의 matrix의 일부입니다. 저기서 $w_{11}$은 input vector의 첫번째 원소 $x_{1}$에서 hidden vector의 첫번째 원소 $h_{1}$으로 연결시키는 가중치입니다. 즉, 11에서 앞의 1은 input vector 원소 번호(인덱스), 뒤의 1은 hidden vector의 원소 번호를 의미합니다. W*의 경우 W의 input vector가 hidden vector로, hidden vector가 output vector로 바뀌는 차이점 외에는 전부 같다고 생각하시면 됩니다.
이제 h가 무슨 값인지 알아야 하는데 우선 예시에서 W의 사이즈는 4 x 5입니다. input vector가 4차원인데 hidden vector를 5차원으로 만들어주는 점, fully connected이기 때문이죠. 재밌는 점은 input vector인 x가 1개 값을 빼고 전부 0이기 때문에 W와 곱하면 row 1개를 제외하면 전부 0값을 만든다는 점입니다.

이는 vector와 matrix 간의 행렬 곱 관계를 보면 알 수 있습니다. $\textbf{x}^{T}$ 빨간색 부분만 1이고 나머지가 0이라면 행렬 곱을 할 때 빨간 부분이 W에 영향을 미치는 곳은 3번째 줄만 한정되는 것을 볼 수 있습니다.
※ 논문에서는 $\textbf{W}^{T}$에 x를 곱하는 것을 볼 수 있는데 표현이 다른 것 뿐 결과는 같습니다. 다만 output shape가 1 x 4로 논문에서 기대하는 4 x 1이 전치된 결과를 가집니다. 저는 이해를 쉽게 하기 위해 이렇게 표현했습니다.
즉, h의 결과에서 나머지 $\textbf{x}^{T}$값인 0을 곱하는 곳은 전부 0이므로 실질적으로 $\textbf{x}^{T}$와 W를 행렬곱하면 빨간 부분만 서로 곱하여 나온 결과라고 판단할 수 있습니다. 논문에서는 이를 $v_{wI}^{T}$라고 하는데 이는 $w_{I}$라는 단어를 embedding 했을 때 결과값을 의미합니다. 우리 예시에서는 'your'이라는 4차원 단어를 임의의 5차원 단어로 바꾼 것입니다.
그 다음 $u_{j}$라는 layer 값을 구하려고 하는데 그림은 다음과 같습니다.

그림 3을 보면 j번째 layer값을 구하는데 여기서는 j를 4로 놓겠습니다. W*는 5 x 4의 shape를 가지는데 이는 5차원을 다시 4차원으로 만들기 때문입니다. u의 4번째 원소값을 구하려면 W*의 4번째 column만 이용하면 됩니다. 그러기 때문에 논문에서도 j번째 column을 이용하여 u의 원소를 구하는 것을 볼 수 있습니다. 여기서 W*의 4번째 column을 논문에서는 $\textbf{v}\prime_{w_{j}}^{T}$라고 하는데 이는 $w_{j}$라는 단어를 embedding 된 5차원 형태로 나타낸 것이며 예시에서는 'name'이라는 단어를 의미한다고 생각하면 됩니다.
식을 정리하면 $\textbf{v}\prime_{w_{j}}^{T}$ h입니다.
여기까지가 input에서 output까지 가는 흐름도였습니다. 이제 $w^{I}$(your)라는 단어를 넣었을 때 $w^{j}$(name)이라는 단어가 나올 확률을 보도록 하겠습니다. 식을 보면 $exp(u^{j})$ / $\sum_{j\prime = 1}^{V} exp(u_{j\prime})$으로 되어있는데 이는 softmax 함수를 이용한 것으로 우리 예시를 빌리면 uj, 즉
name이 나올 수 있는 정도 / 모든 단어가 나올 확률
이라고 생각하시면 됩니다. 즉, 모든 단어의 $u_{j}$ 값을 합치면 1이 넘기 때문에 이를 1로 정규화 시키는 것입니다. 그 다음 식은 우리가 위에서 구한 식을 토대로 $u_{j}$를 embedding 된 input vector, output vector로 바꾼 표현입니다.
2. weight 수정 과정(학습)
자, 이제 마지막으로 weight가 update 되는 과정입니다. backpropagation이 연관된 내용이기 때문에 미분, 딥러닝에 대한 사전지식이 있어야 합니다.
우리의 목표는 input 단어를 넣었을 때 output 단어를 잘 맞출 수 있도록 모델을 만드는 것입니다. 즉, 'your'이라는 단어를 넣었을 때 'name'이라는 단어가 나올 것이라는 확률을 극대화 시키는 것입니다. 이를 수식으로 표현하면 다음과 같습니다.
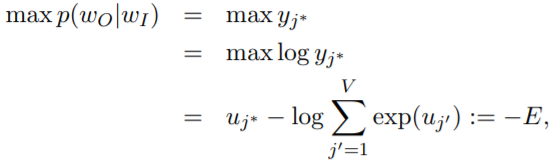
여기서 확률 극대화 식에 '-'인 negative를 붙이면 최소화 할 식으로 바뀌게 됩니다. 즉, 우리가 아는 loss function으로 바뀌는 것입니다.
이제 weight를 update하기 위해 각 weight 별로 미분해보도록 하겠습니다. 우리가 가진 weight matrix는 W와 W*이므로 이 2개를 update하는 식을 만들면 모델의 학습구조를 완전히 이해하는 것입니다.
첫번째로 E를 $u_{j}$로 미분한 결과입니다.

여기서 $t_{j}$는 output 단어가 실제 단어일때만 1이며 나머지는 0인 값입니다. 즉, 'name'이라는 단어라면 $t_{4}$만 1이라고 $t_{1}$, $t_{2}$, $t_{3}$은 0이 됩니다. $y_{j}$는 우리가 예측한 확률값이므로 $y_{j}$, $t_{j}$의 차이값은 error 값이 됩니다.
다음으로 W*의 원소인 $w*_{ij}$를 보도록 하겠습니다.

식을 보면 $u_{j}$ / $w_{ij}\prime$ 부분이 $h_{i}$로 바뀌는데 이는 위의 식에서 $u_{j}$ = $v\prime_{w_{j}}^T \textbf{h}$라는 식, 그림3과 관련있습니다. 그림 3을 보면 h랑 W*랑 행렬곱을 할 때 h의 i번째 랑 W*의 i번째랑 서로 매칭 되는 것을 볼 수 있습니다. 즉, $u_{j}$를 구할 때 $w_{1j}$ * $h_{1}$ + ... + $w_{5j}$ * $h_{5}$로 식이 되기 때문에 $u_{j}$를 $w\prime_{ij}$로 미분하면 $h_{i}$만 남게 되는 것입니다.
그래서 $w\prime_{ij}$를 update 하면 $w\prime_{ij} - \eta * e_{j} * h_{i}$가 되며 여기서 $\eta$(에타)는 learning rate가 됩니다. 이를 바꿔 표현하면 다음과 같은 식이 됩니다.
이는 $w\prime_{ij}$는 $v\prime_{w_{j}}$의 i번째 값이며 $w\prime_{1j}$ ~ $w\prime_{5j}$까지 하면 $\textbf{v}\prime_{w_{j}}$가 되기 때문입니다. 그리고 $h_{i}$는 어차피 $w\prime_{ij}$에 매칭되므로 $w\prime_{ij}$ 값에 매칭되는 각 $h_{i}$를 나열하면 이런 식이 됩니다.
이번에는 W에 대한 가중치 update를 보도록 하겠습니다.
우선 E를 $h_{i}$로 미분하면 다음과 같은 형태가 됩니다.

이는 그림 1을 보시면 아시겠지만 $h_{i}$가 $u_{1}$, $u_{2}$, ..., $u_{5}$까지 연관되어 있어 $w * i_{1}, w * i_{2}, ..., w * i_{5}$에 대해 모두 계산해야 합니다. 그래서 이러한 식이 만들어지게 됩니다. $EH_{i}$로 우리는 이 결과를 정의하겠습니다.
다음으로 $h_{i}$를 구할 때 그림 1을 보시면 아시겠지면 각 input과 그에 대응하는 가중치 값이 있으면서 다음과 같은 식이 만들어집니다.

위 2가지를 이용하여 우리는 W*의 값인 $w_{ki}$에 대해 다음과 같은 미분식을 구할 수 있습니다.

여기서 tensor product로 E를 W로 미분한 결과를 나타내면 다음과 같습니다.

이는 $x_{1}$에 대해 $EH_{1}, EH_{2}, ..., EH_{5}$로 미분하며 그 외에 $x_{2}, x_{3}, x_{4}$에 대해서도 $EH_{1}, ..., EH_{5}$로 미분한 결과를 나타냅니다. 즉, 모든 x값과 EH값을 대응하는 형태를 나타낸 것으로 이는 4 x 5의 shape를 가지게 됩니다. 그런데 우리가 input vector에서 x의 1개 값만 빼고 전부 0으로 나타낸 것을 봤습니다. 즉, 'your'에서 3번째 원소 값만 빼면 전부 0입니다. 그래서 위의 tensor product 결과는 $x_{3}$의 값만 빼면 전부 0이며 $x_{3}$도 1이기 때문에 미분 결과는 EH만 남게 됩니다.(미분 결과는 x* EH였으므로) 이를 식으로 나타내면 다음과 같이 됩니다.

어차피 W에서 update 대상은 x의 3번째 원소인 값만 해당하며 이는 우리가 아까 정의한 $v_{WI}$입니다. 그래서 이 부분만 업데이트하는 것이 W 전체를 업데이트 하는 것과 같은 것입니다.
여기까지가 word2vec을 이해할 기본적인 구조였습니다. 사실 모델을 깊게 공부하실 분이 아니라면 이걸 볼 필요는 없습니다. 하지만 저의 경우 모델 구조가 어떻게 돌아가는지 알아야 이 모델의 장단점 공부가 유용하다고 판단하여 하나하나 뜯으면서 공부했으며 이 글로 정리해서 저도 잊어버릴 때 마다 보곤 할 것입니다.
긴 글인데 읽어주셔서 감사드리고 혹시 틀린점이나 궁금한 사항 있으면 꼭! 꼭! 댓글이나 쪽지 등으로 말씀해주세요!
'모델 > 자연어처리' 카테고리의 다른 글
| Text Classification Algorithms: A Survey (알고리즘 파트) (4) | 2020.11.16 |
|---|---|
| word2vec (2) (0) | 2020.08.13 |

